We're going to ship Telescope 1.8 later today, and I wanted to write about some of the things I worked on and learned in the process.
There have been a number of themes in this release:
- A new approach and pace to dependency updates
- Updating our UI for the 2.0 redesign
- Refactoring to Microservices
I'll talk about each in turn.
Dependabot Joins the Team
During the 1.8 cycle, we welcomed a new team member, Dependabot.
Anton and Yuan have both put a lot of effort into refining the process to the point where things are working quite well. I've lost count of how many PRs I've reviewed or seen reviewed to update dependencies over the past two weeks.

We had a bit of a rocky start in our relationship, though. Robots do what you tell them to do, and Dependabot is designed to create PRs. It can create a lot of them quickly if you let it. Like, a lot. Also, it has many helpful features like automatically rebasing its PRs.
Moving fast and fixing things sounds good, but it has some unintended side effects. For one, your CI builds go crazy. I got a surprise email the first weekend we enabled Dependabot from Netlify to tell me that my "Free" account had used too many build minutes, and that I now owed them money. It was interesting to see how different CI providers handled this, actually. Vercel rate limited my account, so we couldn't do new builds, which seems like the right approach to me. I almost ran out of build minutes for the month on CircleCI as a result too.
Now that we've tuned things, it's running a lot better, and the results are quite good. The dependecies are constantly being updated with small version bump after small version bump. I think that this was an intersting experiment to try. It's motivated me to get even more test coverage, so that reviewing these is easier. Our front-end needs tests badly.
2.0 UI Redesign
Pedro, Duke, Josue, Tony, Ilya, Huy, Royce, and Yuan have been iterating on the fronte-end 2.0 implementation. It's been interesting to see two volunteers from the community (Pedro and Duke) doing the bulk of the work, and doing it well. I'd like to get all of the front-end devs working at a more similar pace and collaborating more than they have during this cycle. We have lots to do, and plenty of people to do it. We just need everyone to dig in.
You can play with the new front-end at https://telescope-dusky.now.sh/ as it gets built in real-time. The changes are significant, and it's very cool to see how quickly the major overhaul of the pieces is coming together. I'm enjoying having people on the team with an eye for design and the skills to make it happen in the front-end.
The team has been learning to contend with TypeScript more and more, and the quality of the code is getting better. I'm teaching Angular and TypeScript in another course at the same time, and it's impressive to see how quickly Telescope has been able to shift to TypeScript and embrace vs. fight with it.
Microservices
I've spent the bulk of my time during this cycle focused on paving the way for our move to a microservices architecture. We wrote Telescope 1.0 as a monolith, and it worked well. But one of the main goals I have for this change is to make it possible to disconnect the front-end and back-end (e.g., run on different origins) but still be able to share authenticaton state. The students coming to work on Telescope find it hard to run the monolith locally on their computers, and I want to make it possible to develop the front-end without running a back-end, or make it easy to run just one service locally, and use the rest remotely on staging or production.
I gave a talk to the team last week about the ideas behind microservices, and how they are implemented. It's new for all of the students, and has required me to do more of the initial lifting than I'd hoped. Extracting microservices vs. writing the system from scratch is a lot easier. Much of what we need to do is already there, in one form or another, and the task is to figure out how to divide things up and what needs to get shared and how.
One intial benefit we're already seeing is the value of limited scope for each service. For example, I had a good talk with Chris about the User service he's writing. His code is pretty much finished, but he didn't realize it. I think he was shocked to learn that he wasn't responsible for all aspects of how a user's info flows through the app. "Wait, you mean I only need to write these routes and I'm done!?" Yes! The benefit of a microservice architecture is that you don't have to worry about how the data gets used elsewhere, just that it's available to other parts of the system that need it.
I've had to solve a bunch of problems in order to make this approach possible, and learned quite a bit in the process.
Satellite
My first task was to write a proof of concept service that could be used to model the rest. I chose to rewrite our dynamic image code as a service. The Image Service lets you get a random image from our Unsplash collection. I also included a gallery to show all of the backgrounds. I wrote unit tests for it, to give the team a model to follow with theirs, and then extracted a base package that could be shared by all of our microservices: Satellite. The code in Satellite takes care of all the main dependencies and setup needed to write one of these services, allowing each service to focus on writing the various routes they need. We've used it to write half-a-dozen service so far, and it's been working well. This week I added middleware to support authentication and authorization in routes as well. Speaking of auth...
Authentication and Authorization
My next task was to tackle authentication and authorization. In Telescope 1.o, we implemented a SAML-based SSO sign-in flow with Seneca's identity provider. This required a session to be maintained in the back-end, and since our front-end was being served over the same origin, we didn't have to do anything special to connect the two.
In Telescope 2.0, I want to leverage this same SSO authentication, but extend it with token-based authorization. Here's a diagram of what that looks like:
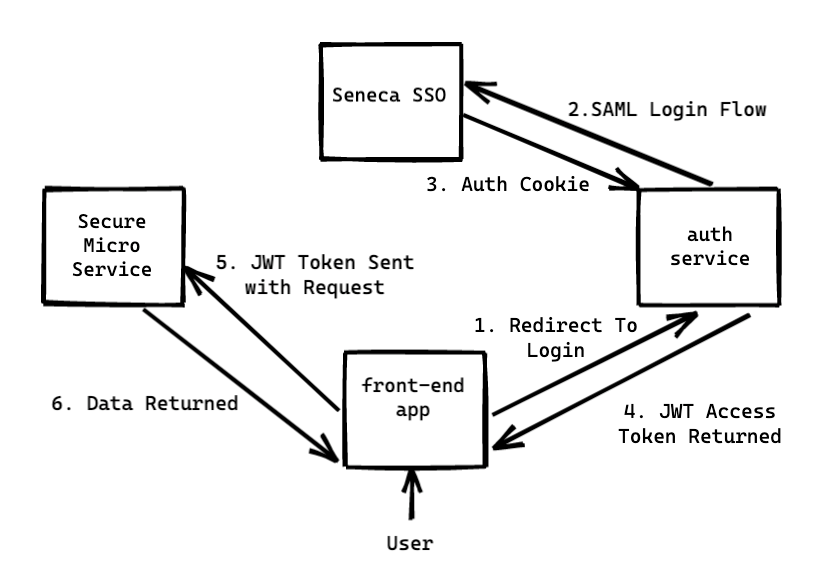
The steps are roughly these:
- A user goes to our front-end app, perhaps https://telescope.cdot.systems or maybe on an external host like Vercel
- The front-end app wants to access a resource on one of our secure microservices, maybe User information.
- The user needs to login, so clicks the Login link in the front-end app. A small bit of state (e.g., random string) is put into
localStoragefor later. - The user is redirected to our auth service:
api.telescope.cdot.systems/v1/auth/login?redirect_uri=https://telescope.cdot.systems/&state=a3f1b3413. The URL contains two things: 1)redirect_uricontaining a URL pointing back to the entry point of the front-end app; 2) our randomstate. The latter is used as a ride-along value on all the redirects that are about to take place, and lets the client know at the end that nothing was tampered with in between. - The auth service receives the request (/
login?redirect_uri=https://telescope.cdot.systems/&state=a3f1b3413) and stores theredirect_uriandstatein the session. It then prepares a SAML message for this user to authenticate, and redirects them to the SSO identify provider server. - The SSO identity provider receives the request to login, and shows the user a login page, where they enter their username and password. This either works or fails, and in both cases, they are sent back to the auth server with details about what happened
- The auth service receives the result of the SSO login attempt at
/login/callbackand examines whether or not the user was authenticated. If they were, we create an access token (JWT) and the request is redirected back to the original app at theredirect_uri: https://telescope.cdot.systems?access_token=...jwt-token-here...&state=...original-state-here... - The frontend app examines the query string onload, and sees the
access_tokenandstate. It confirms thestateis what it expects (e.g., compares to what's inlocalStorage). The token is then used with all subsequent API requests to our microservices. - A request is made to the secure microservice. The token is included in the HTTP Headers:
Authorization: bearer <jwt token here> - The secure microservice gets the request, and pulls the bearer token out of the headers. It validates it, verifies it, and decides whether or not the user is allowed to get what they want. A 200 or 401 is returned.
I've done almost all of the above in two PRs, one that is merged and the other going in today. One thing that struck me about doing this work was how many of the core security dependencies on npm are poorly maintained. It feels like much of this is too important to be left untouched or parked in some random person's GitHub. I wish node had a bit more of it baked in.
Routers, Routers, Routers!
Breaking our back-end into microservices requires a some co-ordination in the form of an API gateway to tie together the various services. In Telescope 1.0, we use nginx to serve our static front-end, and also as a reverse proxy to our monolithic back-end. You can use nginx as microservices gateway too, but I wanted to try something different.
For Telescope 2.0 we're adding Traefik. I've wanted to play with Traefik for a while, and this seemed like a logical time. What I like about Traefik is how it can be integrated with Docker and Docker Compose so easily, both of which we use extensively in production. Traefik is Docker-aware, and can discover and automatically configure routing to your containers.
I've found the docs and API/config a bit hard to understand at times. It's a mix of "I can't believe how simple this is" and "why is this is hard to figure out?" I find that I'm routinely having aha! moments, as I break then fix things.
Here's a quick outline of how it works. We do all of our configuration via labels in our docker-compose.yml files. Here's a stripped down-version of what Traefik looks like with the Auth and Image services:
version: '3'
services:
traefik:
image: traefik:v2.4.5
command:
- '--api.insecure=false'
- '--providers.docker=true'
- '--providers.docker.exposedbydefault=false'
- '--entryPoints.web.address=:8888'
ports:
- '8888'
volumes:
- /var/run/docker.sock:/var/run/docker.sock
labels:
- 'traefik.enable=true'
# image service
image:
build:
context: ../src/api/image
dockerfile: Dockerfile
ports:
- '${IMAGE_PORT}'
depends_on:
- traefik
labels:
# Enable Traefik
- 'traefik.enable=true'
# Traefik routing for the image service at /v1/image
- 'traefik.http.routers.image.rule=Host(`${API_HOST}`) && PathPrefix(`/${API_VERSION}/image`)'
# Specify the image service port
- 'traefik.http.services.image.loadbalancer.server.port=${IMAGE_PORT}'
# Add middleware to this route to strip the /v1/image prefix
- 'traefik.http.middlewares.strip_image_prefix.stripprefix.prefixes=/${API_VERSION}/image'
- 'traefik.http.middlewares.strip_image_prefix.stripprefix.forceSlash=true'
- 'traefik.http.routers.image.middlewares=strip_image_prefix'
# auth service
auth:
build:
context: ../src/api/auth
dockerfile: Dockerfile
ports:
- ${AUTH_PORT}
depends_on:
- traefik
labels:
# Enable Traefik
- 'traefik.enable=true'
# Traefik routing for the auth service at /v1/auth
- 'traefik.http.routers.auth.rule=Host(`${API_HOST}`) && PathPrefix(`/${API_VERSION}/auth`)'
# Specify the auth service port
- 'traefik.http.services.auth.loadbalancer.server.port=${AUTH_PORT}'
# Add middleware to this route to strip the /v1/auth prefix
- 'traefik.http.middlewares.strip_auth_prefix.stripprefix.prefixes=/${API_VERSION}/auth'
- 'traefik.http.middlewares.strip_auth_prefix.stripprefix.forceSlash=true'
- 'traefik.http.routers.auth.middlewares=strip_auth_prefix'
I've left some comments, but notice a few things:
- We enable Traefik for each docker container that we want routed using
traefik.enable=true - We define a unique router per-service by assigning a name, for example:
traefik.http.routers.auth.*vs.traefik.http.routers.image.* - We specify rules for how Traefik should route to this container, for example defining a hostname and/or path prefix:
traefik.http.routers.auth.rule=Host(${API_HOST}) && PathPrefix(/${API_VERSION}/auth)will mean thathttps://api.telescope.cdot.systems/v1/authgoes to our auth container in production (local and staging use different hostnames). - We define middleware (e.g., altering URLs, compressing, authentication, etc) using
traefik.http.middlewares.name_of_our_middlewareand then adding the options for that middleware. For example, stripping the /v1/auth prefix on URLs.
It's pretty much that easy. Via environment variables we can use the same config in development, CI, staging, and production. For 1.8 we're going to ship 1.0 and 2.0 running in parallel, and use nginx to manage SSL certificates, compression, caching (Traefik doesn't have this yet, but nginx is amazing at it), etc. Here's what it looks like:
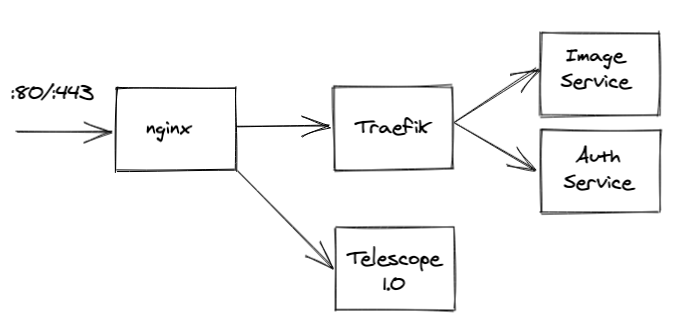
Docker
To get all these services to work, I've had to spend a lot of time reworking our Docker and Docker Compose strategies. I wanted to make it easy to run things locally, in GitHub Actions, and in production. Doing that with the least amount of hassle required a few things:
- I've created 3 different
envfiles for development, staging, and production. One of the interesting things I learned this week is that you can a) use overlay docker-compose files (have one extend another); and b) define the files you want to use in theCOMPOSE_FILEenvironment variable. This means that running our entire system can be reduced todocker-compose --env-file env.development upordocker-compose --env-file env.production up. - Our approach uses environment variables a lot for the different configurations, and it's not possible to share them between multi-stage docker builds. Josue and I spent a bunch of time scratching our head over this. Apparently you need to use build time
ARGs instead. By carefully using a mix ofENVandARGwe were able to accomplish our task, but it wasn't obvious at all. - We used to use sed to replace strings (e.g., domains) in our nginx.conf file, but I learned that you can do it with a
*.conf.templatein the dockerized nginx. - There's a nice npm module that wraps docker-compose for JS devs who don't know how to invoke it directly. I wrapped all of our microservices invocations in some JS scripts to make it easier for the students.
E2E Testing
With our microservices in place, and Docker and Traefik taking care of routing everything nicely, I needed to figure out a solution for end-to-end testing. Writing unit tests for the image service was fairly straight forward, but the auth service requires complex interactions between at least 4 different apps, 2 of which need to run in Docker.
I spent quite a while re-working our Jest config, so you can run unit and e2e tests from the root of our project. I've never had to create a Jest configuration this complex, but lots of other people have, so there were good docs and lots of examples on GitHub.
In the end, Jest can take care of starting and stopping our microservices in Docker, running the tests across all the various services, and do it all with a single command from the project root.
Using this I was able to write automated auth tests using Playwright. I tried a few different frameworks before settling on Playwright, and it was the need to handle redirects smootly in automated tests that Playwright did better than anything else. With Playwright I can write tests that run in headless versions of Chrome, Firefox, and WebKit, and simulate user interactions in the browser with only a few dozen lines. It's literally amazing. Seeing the tests running in GitHub Actions was very satisfying.
Conclusion
I'm hoping to see all this work shipped in a few hours after our class meets. It's been a lot of work for me to get all these pieces in place, but now that they are, we should be able to write, test, and ship code a lot faster.
I'm hoping that by 1.9 we'll have all the services roughly in place and we can start moving away from the 1.0 back-end toward the new stuff.