ChatGPT continues to rule the news cycle. It's also increasingly finding its way into my work on our department's Academic Integrity Committee, where we've seen it pop up more and more in reported cases: students using it on tests, both paper-based (cell phone pic of a question uploaded to a WhatsApp group, where a friend types it into ChatGPT) and electronic, as well as in assignments. Much of the academic dialog online and at our institution has been focused on ChatGPT as a vector for cheating.
Meanwhile, a decade's worth of innovation has happened in the past few weeks as an arms-race plays out for control of AI in big tech. I was trying to keep track of everything I saw being released, but it's impossible. The rate of change is beyond anything I've ever experienced. The idea that an instructor or institution can write a policy that gets on top of this is laughable.
Despite my concerns over academic integrity, I'm more interested in understanding how to properly use AI in teaching, learning, and development. As a result, I've been trying to take inspiration from people like Simon Willison, who is using ChatGPT and Copilot to learn new technologies (e.g. Rust, AppleScript) and taking notes as he goes.
So this past week I challenged myself to try and use ChatGPT in order to better understand how my students are encountering it, and what lessons I could learn in order to teach them how to make better use of the responses they are getting.
I started the challenge by building ChatGPT in CSS for my second-semester web programming class. We were studying CSS Layout, and the ChatGPT site is a fairly simple one to create, using the topics for the week:
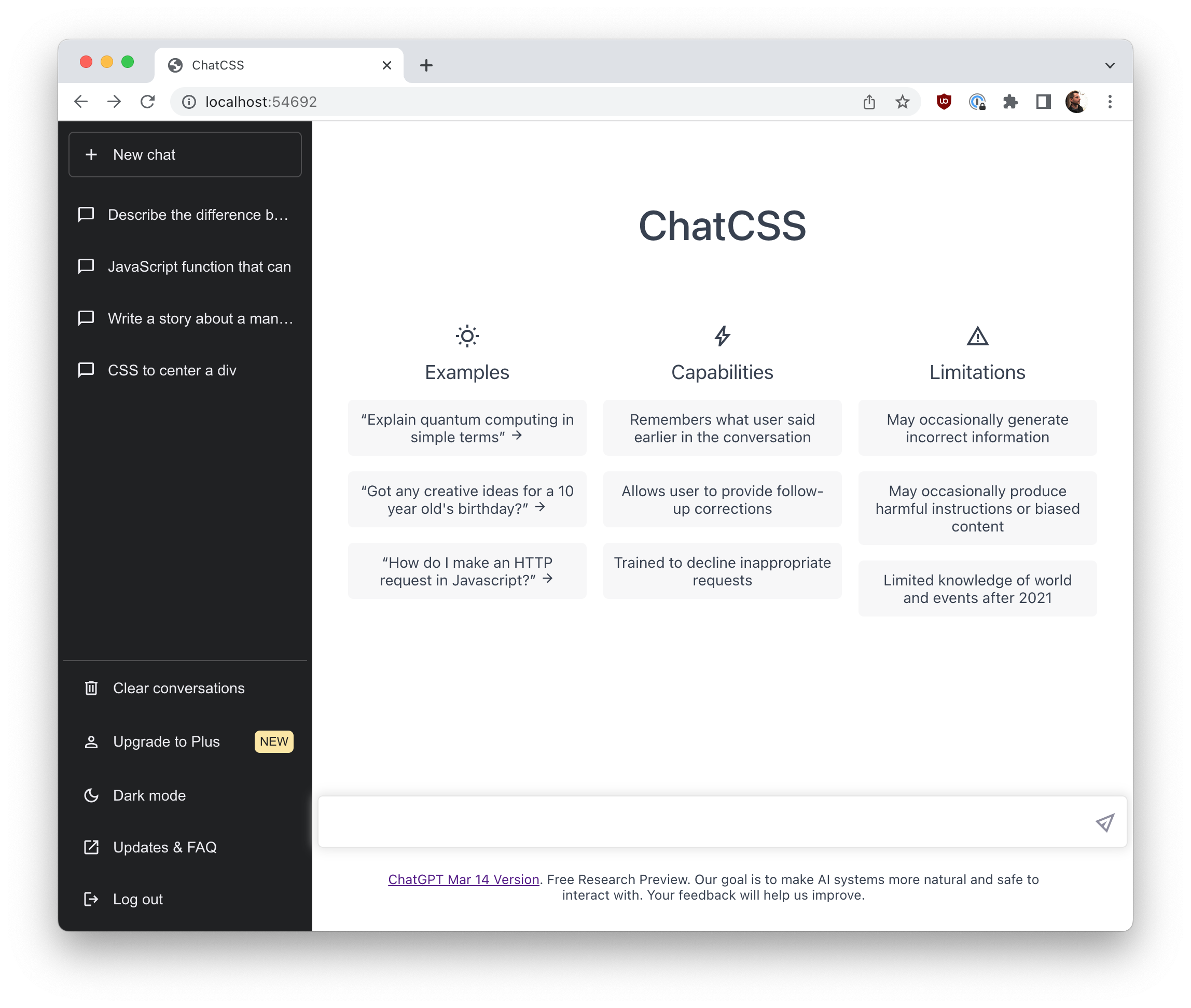
Writing the code, I spent a long time using their interface. I was struck by the Limitations column, which I doubt most people have read:
- May occasionally generate incorrect information
- May occasionally produce harmful instructions or biased content
These are incredible warnings to see displayed on a web site. "This site might harm you." Wow! We could argue that this warning should be placed on lots of the web, but to see it called out like this is fascinating and not something I encounter very often. I thought about that a lot this week.
I went to class on Monday, plugged my laptop in, and started with this ChatCSS tab open. "Does anyone recognize this site?" Silence! Eyes down. Nervous laughter. It was like I had just begun a lecture about sex. It's clear that ChatGPT has quickly earned taboo status in academic discourse between professors and students. That's too bad, because I believe it needs to get discussed openly.
Spending two lectures this week building the ChatCSS UI and talking about how it works allowed me to start to engage with the students, hear their ideas, discuss their questions. They are absolutely using it, but mostly having to hide that fact. They need help navigating this new world. From this experience I realized that I need to talk about it more, not less.
Next, I did a bunch of reviews for my open source students working on the Starchart DNS/SSL project. A number of times as I read their code, I asked questions about what I was seeing, and the answer came back, "ChatGPT recommended this." I've never encountered this before. ChatGPT was a third entity in our conversations, always there but also completely absent. For example, it wanted to use a 403 HTTP status code to indicate that a resource being created asynchronously isn't ready yet (I'd use a 409). Or writing regular expressions to cover validation cases on IPv4, IPv6, and domain names. I wanted to know about edge cases that were missed. Having ChatGPT's output, but not ChatGPT itself, made the process a bit painful. The code raised questions that couldn't be answered, which felt unsatisfying. I learned that detaching text from a ChatGPT response, but still insisting that "ChatGPT wrote it" won't work. Once you pull that text out of the ChatGPT window, you have to own it, answer for it, clean up after it.
I had a number of times this week were I struggled to name something in code, and I tried using ChatGPT to help me explore possible options. For example, we have been dealing with overlaps between name vs. subdomain vs. fqdn in our Starchart code. I didn't end up using a lot of what it suggested, but I think the exercise of forcing myself to get it out of my head, and into written form, helped me come to a decision faster. In this way, using ChatGPT was a forcing function. Much as writing an email to a colleague, or discussing with peers on Slack, writing my problem out kickstarted the problem-solving process.
Later in the week I used ChatGPT to solve a real problem I had. I was struggling to write some GitHub Actions code for a Docker build and webhook deployment flow. GitHub Actions are annoying to test, because you have to do it for real vs. running things locally. I couldn't figure out or remember how to do the following:
- Interpolate environment variables into JSON strings
- Get a short git sha (I only wanted the first part of the string)
I found ChatGPT was eventually able to get me where I needed to be, but it took half-a-dozen questions/responses to get there. For example, it told me to use the substring function:
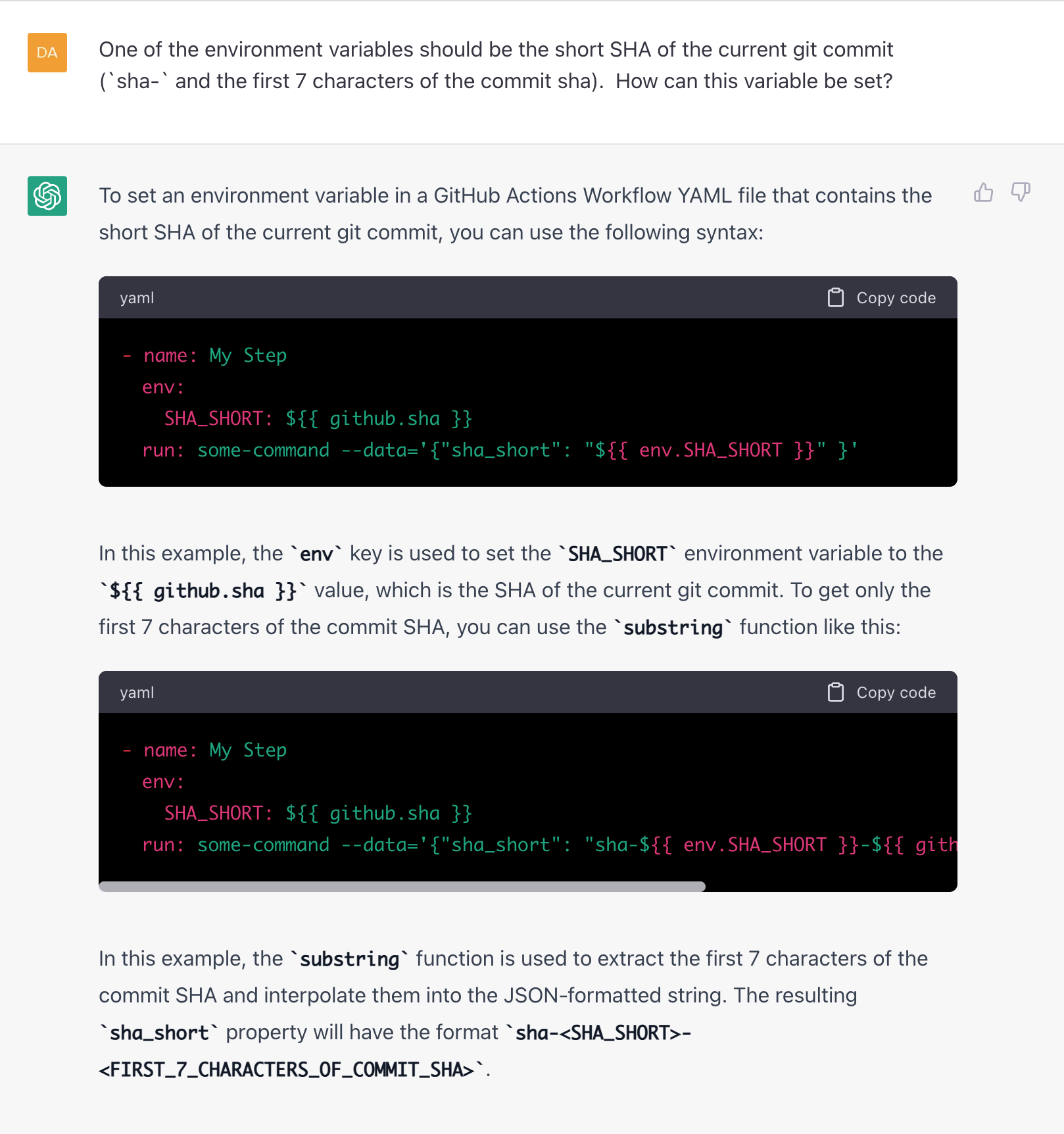
However, there is no such function (GitHub, please add it!), so I had to press it:
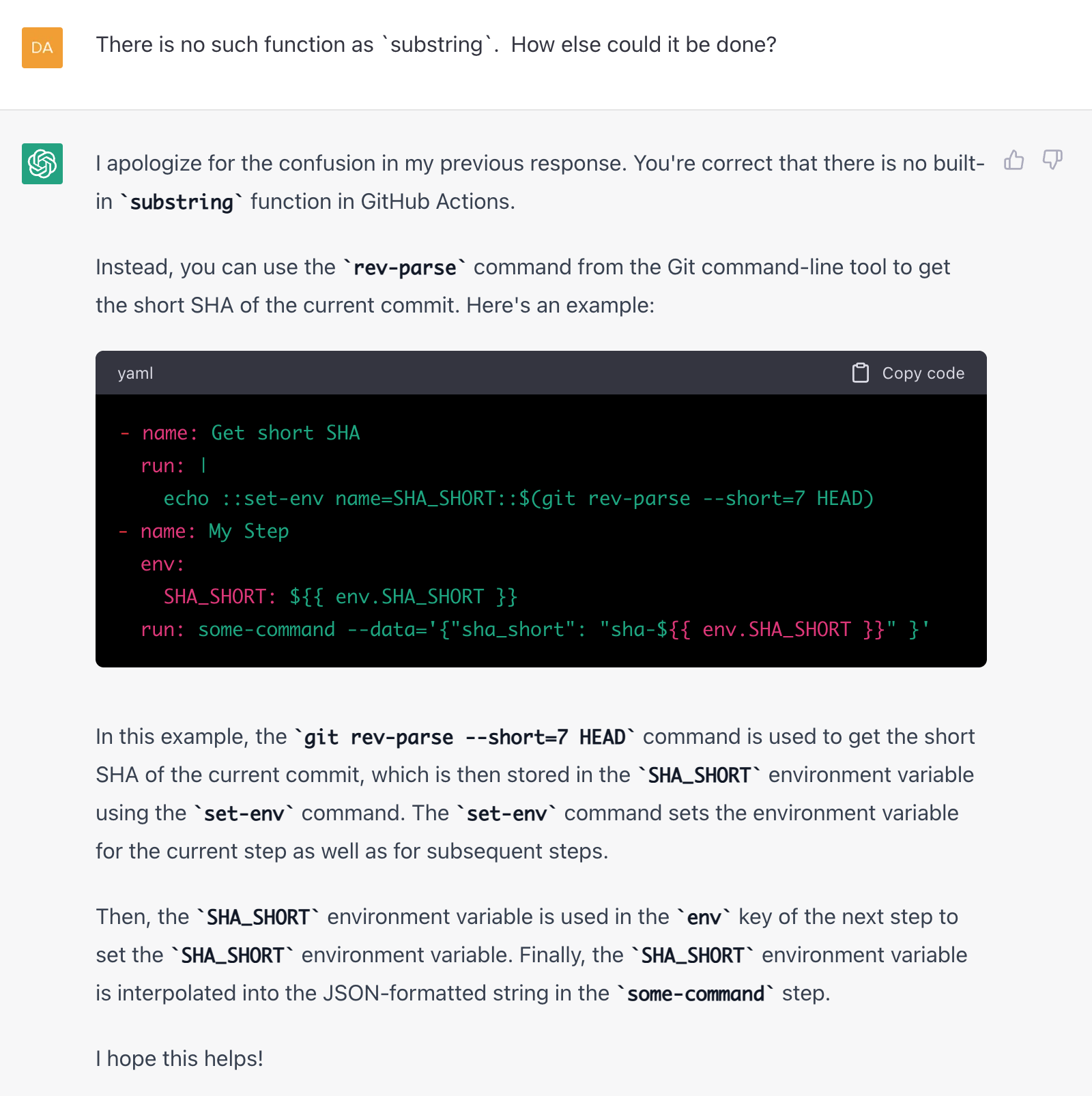
It did help, and I was able to write my workflow YAML file and get automatic deploys to work.
Next, I struggled to make sense of the BullMQ API for dealing with errors in flow jobs. We have a series of asynchronous worker jobs that run in the background, and we need to chain them. When one of them fails, we need to execute an error handler, and the way we were doing it was not working.
I was pleased to discover that simply mentioning the name of the library, BullMQ, was enough and it knew what I was talking about. However, once again, I had to be patient to arrive at my desired destination. I went back and forth with it many times before I could get it to stop hallucinating imaginary APIs and had to explicitly call out its inconsistency:

Not only is ChatGPT going to give you incorrect info, but it also has no problem contradicting itself in a single response. This is something I'm not used to. If a person did this to me, I'd get annoyed; in fact, I was annoyed in the exchange above. Humans won't tolerate being lied to or manipulated like this. This erosion of trust breaks down communication: "How can I trust you if you just lied to me?" The truth is, you can't trust ChatGPT. It neither lies nor tells the truth, flitting effortless between the two, giving what Neil Gaiman called "information-shaped sentences" on Twitter this week.
You have to approach ChatGPT with zero-trust and plan to verify everything. Knowing this, I can route around incorrect information, and try to aim deeper at the truth I really need. This tells me that using responses in areas I know nothing about is going to leave me vulnerable to misinformation. My students, who don't know enough yet to push back at the AI, will struggle when it gives reasonable but false code.
Later in the week, I asked it to rewrite a TypeScript file I was reviewing. I wanted to see what other styles it could imagine for the code, which was somewhat complex to read. It did a nice job of renaming things, switching loop types to make it more readable, using early returns (amen!), etc. It also broke the logic of the code. When I shared it with the original author, he wasn't impressed. Where I found the style vs. the substance of the code interesting, he was 100% focused on the substance, which had problems. This taught me that I need to be clear about my expectations for the use of the text I share from ChatGPT: am I looking for truth or form or both? What does my audience need and expect?
Next, I had some free time and wanted to figure out how to get Microsoft's Megadetector model running with node.js and TensorFlow. I'm really interested in Camera Traps and biodiversity tracking using technology. I spent a long time going back and forth with ChatGPT on this one, before eventually giving up. First, it gave me code to use it remotely via Azure vs. locally (not a bad idea, actually). Once I told it that I wanted to run the model locally, it got me 80% of the way there. However, it gave me invalid model URLs, combined Python/pip and node.js/npm dependencies, and made-up an npm module for the image processing. Once again, I had to be willing to sort through the response and push back in order to have it correct its mistakes.
This can feel uncomfortable, too, since a human at the other end of my needy and critical responses would quickly tire of our conversation. ChatGPT doesn't, and will happily try again. Eventually it became clear that the 2021 model cut-off date wasn't going to work with the current state of the Megadetector repo, and I ran out of time. However, if I'd been willing to keep going a bit longer, I could have got something working.
Next, I decided to port some Python code I'd read online to Zig. I don't know why I've been interested in Zig lately, but I keep coming back to it (I think where Rust feels too much for me, Zig somehow feels just right). I was pleasantly surprised to see how easily this process went. Once again, it hallucinated a mix of pip modules and zig standard library code; however, by now I was used to sorting out the 20% of the response that would need to be thrown away. I liken the process to working with a senior dev who only has 5 minutes to answer your question: the response they give is "right" but includes a mix of real and pseudo-code that you have to expand and debug yourself. Knowing how to set my expectations (that I'll almost never be able to use code it returns as-is, that responses won't be idiomatic to the ecosystem I'm targeting and will often mix ideas from different languages) has made the process less frustrating for me.
Next I tried something completely different and more risky. Having read this thread about a guy who used ChatGPT to help save his dog's life, I tried doing some medical research. Given everything I've said above about needing to be able to verify all responses, not being able to trust at least 20% of what comes back, etc. you might think this is insane. Again, expectation setting is key here. I can't use what it gives back as-is, but by now I don't plan to ever do that. Here, I'm interested in having it guide and inform my research.
I asked about a condition I wanted to know about, starting by asking what the usual way of treating it would be (i.e., without me saying anything). I wanted to see if it could give me information I already know to be true, before going into areas I'm less sure about. It was able to confirm current treatment options, which I know are correct. I then asked for the state of the research into newer methods: what's emerging? It gave me 3 amazing jumping off points, which led me on a fruitful literature review and opened my eyes to some interesting possibilities I hadn't heard about. Here I needed to pair ChatGPT with research into the scientific literature. Unlike code, where I can lean on a mix of my own understanding and tools to verify what I'm being told, I have no ability to assess the value of medical information. One needs to be ready to jump out of ChatGPT and into proper research, but doing so can be a really valuable exercise. I know from experience that I could never get Google to give me this info (I've tried)--I don't know how to put it into a searchable question format. However, after working with ChatGPT, Google once again becomes useful, since I have keywords I can use for search.
Finally, I used ChatGPT to help me quickly do a task that would have been time-consuming to code or do manually. I had a bunch of CSS, and I wanted a sorted list of all the unique CSS properties I'd used. I pasted the entire file into ChatGPT and told it to give me exactly that, which it did. This was probably the most satisfying use I'd had all week. It was something I knew how to do manually, and could also write a program to do, but I wanted it done fast without doing either of those. It "just worked" and got it 100% correct. It made me realize that this kind of language/text programming problem is something I should be feeding to ChatGPT more often. I do a lot of it while teaching, coding, and in my daily life.
This week I found that I had to force myself to use ChatGPT, it wasn't my default. I found the realities of using it both more and less magical than expected. As predicted, I can't trust it. However, if I enter the conversation somewhat adversarially, I can often extract something useful. I'm not talking to AI. We're not chatting. It's much more combative, defensive, and frustrating than talking to a person. I have to verify everything I'm given, which means I have to be in the mood to do that. I can't be tired and let the response wash over me. But I also recognize the value of what I was able to do with it this week. I solved real problems, from technical to academic to personal. It's interesting and I need to try it more.